

Caveat Lector: This is a Junk Drawer post — more documentation for me than an interesting read for you.1 This is part five of an ongoing series exploring a measure on complexity. These posts explore (in excessive detail) an idea due to
from his A Formula for Meaningful Complexity post last April.If you need to come up to speed, see: Part 1, Part 2, Part 3, and Part 4. The first two posts laid out the groundwork. The second two dived into image complexity. Now we get into text complexity.
As with the images, measuring the complexity of text requires a set of texts to measure. With the images, I used large camera photos I could resize to smaller versions. That’s obviously not possible with a text. I also had a variety of other images from complex to simple.
The Text Files
The largest “regular” text file I have is a plain text version of
’s In the Beginning Was the Command Line, a humorous and engaging essay he wrote in 1999.2 I’ll refer to it here as Command orcommand.txt — the text file has 213,063 bytes.I also have text files of Shakespeare’s plays. I used three well-known ones: Hamlet, Romeo and Juliet, and Macbeth. They weigh in, respectively, at 188,602 bytes (6,047 lines), 149,102 bytes (4,772 lines), and 109,288 bytes (3,880 lines).
An interesting aspect of the plays is their formatting:
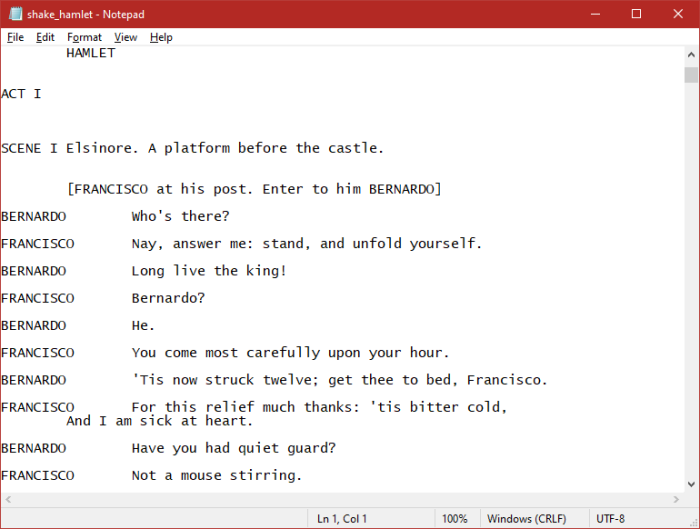
In contrast to Command, which consists of multi-sentence paragraphs separated by blank lines, three things stand out. Firstly, a lot more separate lines but no paragraphs. The longer bits of dialog, and certainly the soliloquies, are line-wrapped, so the longest physical text line in any of the three files is 73 characters.
Secondly, the use of uppercase for names and heading words like “ACT” or “SCENE”. As you’ll see in another post, I decided to treat those separately, which made for some interesting (albeit not hugely helpful) results.
Thirdly, the extreme formatting involving characters’ names and dialog.
On the smaller end of the size scale, I used the text of three of my longest WordPress blog posts. The largest, a description of a fun business trip to Boston, is 37,805 bytes. The other two are about HBO’s Westworld (season one), which impressed me considerably.3 They have 26,812 bytes and 22,717 bytes. Here they’re referred to as post-016714.txt, post-010486.txt, and post-010482.txt, respectively.4
I also generated a set of four text files in which the line-length varies widely but the content is a repeated token. The first file repeats “A”, the second “AB”, the third “ABC”, and the fourth “ABCDE” (I skipped “ABCD”):
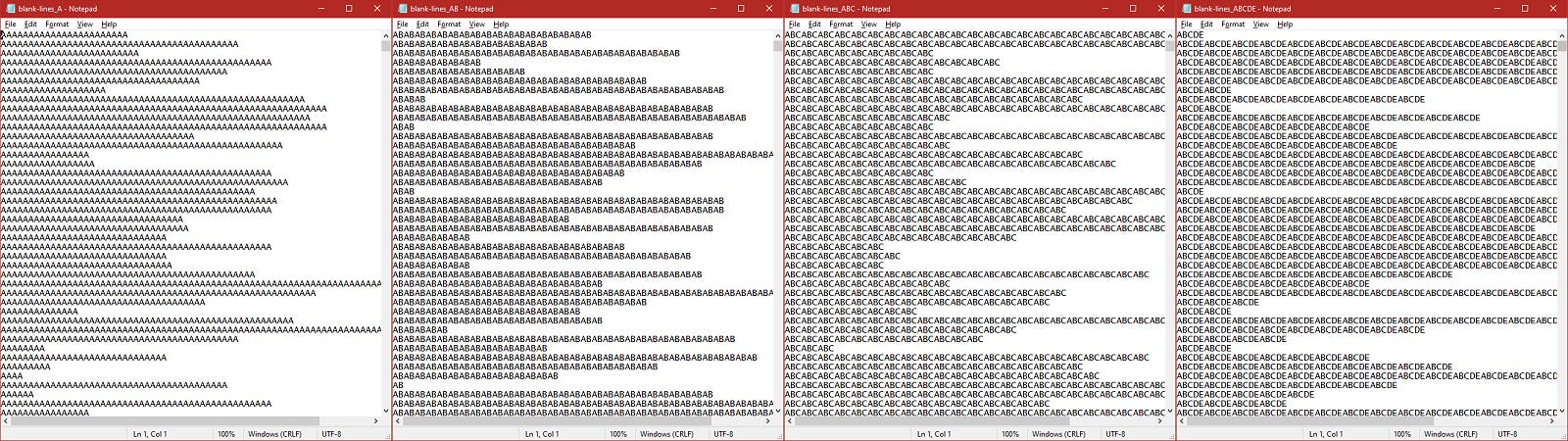
These are referred to as blank-lines_A.txt (and so on) because the algorithm I wrote to generate them uses spaces as the default token.5
Finally, I generated four different kinds of random text files:
random-words.txt— 204,474 bytes — content is words randomly pulled from a file of words extracted from 14 years of my WordPress blog posts. The generating algorithm constructs sentences, paragraphs, and sections, so the text looks like normal text but is gibberish.random-text.txt— 203,564 bytes — content is random characters grouped into words, sentences, paragraphs, and sections. As with the above, it’s formatted to look like regular text, but in form only.random-chars.txt— 204,472 bytes — content is 4400+ lines of varying length and consisting of randomly selected characters from: “a”, “b”, “c”, “d”, “e”, and “f”.random-bits.txt— 201,194 bytes — content is 996 lines, each with 200-character length and consisting of random “0” and “1” characters.
Here’s a sample from random-words.txt:

Here’s a sample from random-text.txt:

Here’s a sample from random-chars.txt:
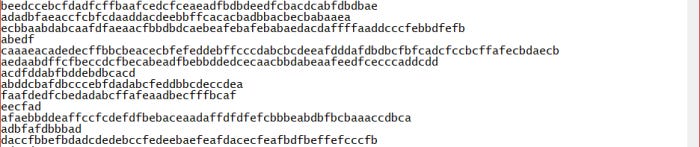
Here’s a sample from random-bits.txt:

The former two make an attempt at normal text structure (syntax without semantics). The latter two are just random strings but with a limited character set. The last one, because of the consistent line-length, is the most regular other than the random “0” and “1” characters.
Text File Noise
There are different ways to add noise to text files. Only one is useful in fully randomizing the text file — the one that changes all bytes of the file to random eight-bit values (essentially the same thing we do with image files).
Just as using random grayscale pixels in image file results in a compressible file even with 100% noise, other ways of adding noise to text result in compressible files.6 So, all calculations here use full randomizing.
I’ll note this results in illegal UTF-8 files because UTF-8 has multi-byte sequences. Randomly altering single bytes can result in illegal multi-byte sequences.7 This doesn’t affect compressing these files, and we don’t care whether we can open them as text files, so it’s a minor point. But it did contribute to my exploring other ways of adding noise that didn’t output illegal UTF-8.
Command Compression Curves
Here’s the compression curve for command-0.txt:
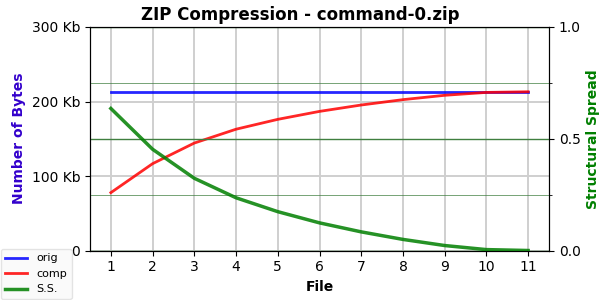
It’s called command-0 here because there are other versions (2-5 & 9) that take different (not particularly useful) approaches. Of some interest here are command-1 (which is the same text backwards) and command-2 (which is the same text with the words scrambled). I was curious about structure versus content. All three versions have identical structure and syntax — whitespace and punctuation are maintained. But only the first is sensible.
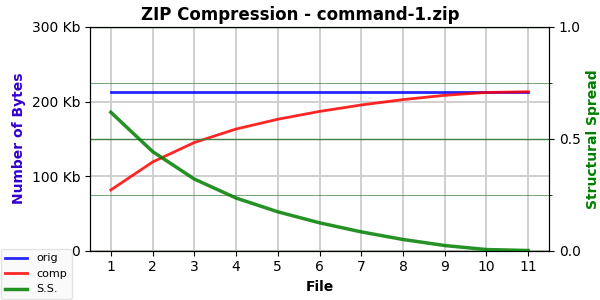
Here’s the curve for command-1.txt:
And here’s the curve for command-2.txt:
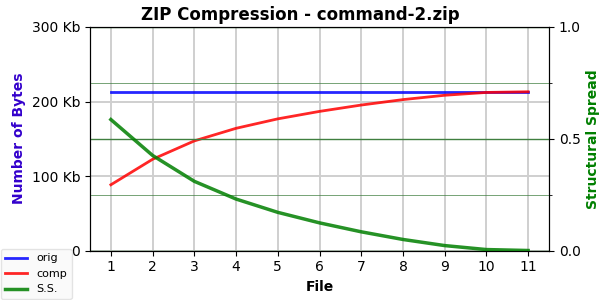
They are essentially identical. And their calculated AC, SS, EF, and ESC values are very close … but not identical:
command-0: 77,661; 0.635502; 2.322504; 114,624.24
command-1: 81,287; 0.618484; 2.283728; 114,813.71
command-2: 88,215; 0.585968; 2.215555; 114,524.51
So, it really seems we are picking out something here with these numbers. Note how the original is the most compressible. Simply reversing the words makes the file slightly less compressible. Scrambling the words makes the file even less compressible.8
The latter doesn’t surprise me. Writing contains repeated phrases (“doesn’t surprise me”, for instance). Compression leverages these repeated phrases. Scrambling the word order reduces, if not eliminates, repeated phrases.
The former did surprise me a bit. Those repeated phrases should be repeated (in reverse order) when the words are reversed. I wonder if it has something to do with capitalization. I don’t alter case, so a capitalized word that was the start of a sentence would likely appear in the middle of a sentence. This might affect compression.9
Hamlet (et al.) Compression Curves
Here’s the curve for hamlet-0.txt:
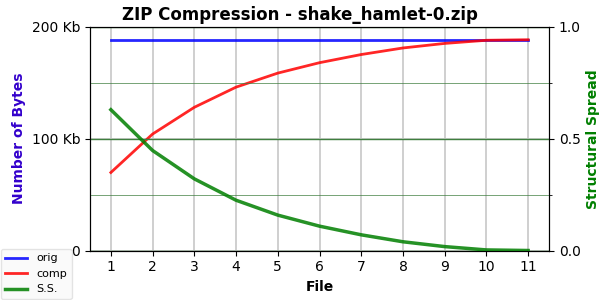
The other two plays are similar.
Here, again, there is hamlet-1.txt and hamlet-2.txt (and others).
The numbers for the three Hamlet versions (188,602 bytes) are:
hamlet-0: 69,785; 0.629988; 2.431601; 106,902.21
hamlet-1: 75,217; 0.601187; 2.384838; 107,841.08
hamlet-2: 78,433; 0.584135; 2.374167; 108,773.52
Here are the matching numbers for Romeo and Juliet (149,102 bytes):
romeo-juliet-0: 55,097; 0.630474; 2.427791; 84,334.80
romeo-juliet-1: 59,774; 0.599107; 2.378053; 85,160.45
romeo-juliet-2: 62,695; 0.579516; 2.353031; 85,492.11
And here are the numbers for Macbeth (109,288 bytes):
macbeth-0: 40,974; 0.625082; 2.431328; 62,271.48
macbeth-1: 44,448; 0.593295; 2.385547; 62,908.71
macbeth-2: 46,006; 0.579039; 2.358269; 62,822.55
All three plays follow the pattern set by Command. The reversed version is less compressible, and the scrambled version even less. That said, all three versions have a high compression value. And note that those values are pretty consistent across the three plays.
So are the EF values. Rounded to a single decimal digit, they are all 2.4 (whereas there was more variation with the Command versions — 2.32 to 2.22). I suspect the higher values here are due to the formatting of the plays. That provides a lot of structure.
The curves for the three posts don’t provide any surprises (and all look similar):
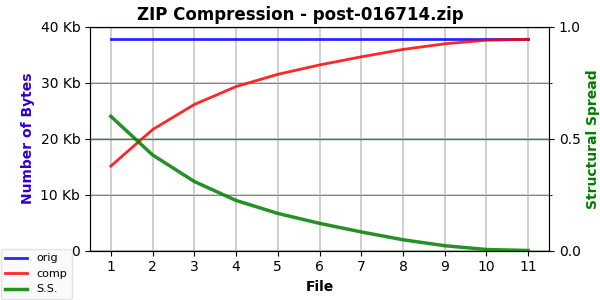
Likewise, their numbers:
post-010486: 9,898; 0.630837; 2.351419; 14,682.31
post-010482: 9,132; 0.598010; 2.343888; 12,800.04
post-016714: 15,115; 0.600185; 2.292918; 20,800.89
We see compression (SS) values around 60% again along with an EF about 2.3 — perhaps a kind of norm for text. This seems fairly consistent.
The ESC values depend on file size, so they vary considerably. We can also see that they capture structure (not content) because they don’t vary much — and not consistently — between normal, reversed, and scrambled versions of the text.
Random Text File Compression Curves
So how does all that compare to the various randomly generated files? The Blank Lines files, not surprisingly, are highly compressible:
ABCDE: 5,176; 0.974602; 1.907269; 9,621.29
ABC: 5,809; 0.971559; 1.787866; 10,090.33
AB: 6,447; 0.968513; 1.693707; 10,575.51
A: 7,015; 0.965765; 1.494215; 10,123.08
All four compress to well under 10% of their original size. More importantly, their EF values are much lower than we saw with “real” text files. These files, of course, have little or no structure.
Note also that the EF values increase with the number of characters in the repeated token. Larger tokens compress better because we replace ever larger chunks of text with references to the token.
The numbers for the Random files vary:
random-words: 73,270; 0.641666; 2.353270; 110,638.66
random-text: 116,249; 0.428931; 1.728881; 86,206.92
random-chars: 74,390; 0.636185; 1.631854; 77,228.77
random-bits: 29,963; 0.851074; 1.519717; 38,753.88
Random-Words compresses much like a normal text file (~60%) and has a “normal” EF in the 2.1 to 2.4 range we saw above. Real words plus a grammatic structure make it “look like” a normal text file.
Random-Text has the lowest EF value because — despite the grammatic structure — the “words” are truly random. This makes the file less compressible. But it does have considerable structure, so its EF value is fairly high (yet still comparable to the “AB” file just above).
Random-Chars is about as compressible as a normal text file, which surprised me a little. Given the small character set, I was expecting higher compression, as in the Blank Lines files. Both feature lines of varying length, so I’m not quite sure why the EF value isn’t higher. Probably due to the lack of repeated sequences.
Random-Bits, no surprise, compresses the best. It’s low EF score reflects its lack of structure. Not quite on par with the Blank Lines files, again due to the lack of repeated sequences.
This has gotten long, so I’ll end abruptly.
Until next time…
Sorry. I spent quite a few hours mucking about with this. It isn’t the sort of project that results in a useful application – just something I found very interesting. A series of posts puts a more tangible value on those hours. Think of these posts as my “research paper”.
For a while, it was available online, although I can’t recall whether it was “officially” available (I think it was, but I could be self-justifying). FWIW, I also own a paperback copy I bought in a bookstore.
It has long been a favorite of mine. The bit in chapter two about the four auto dealerships was beyond LOL — it was FOOMCL (fell out of my chair laughing).
Only to do the opposite as the seasons progressed. A decline even worse than the one M. Night Shyamalan subjected us to in his first movies.
If you want to see them in their natural habitat:
The generator also has parameters controlling the minimum and maximum line lengths. These can be set to the same value to generate a file of same-sized lines.
Which, to satisfy my desire to document this project, I’ll put in an upcoming post that can be safely ignored by the less interested.
For an overview of Unicode, see The Blessing of Unicode on my WP blog. For a longer version that gets into how UTF-8 works, see The Blessing of Unicode on my programming blog.
Although still very compressible.
I’m just guessing.